cStor Overview
cStor is the recommended way to provide additional resilience to workloads via OpenEBS and is the second most widely deployed storage engine behind LocalPV. cStor was originally introduced in OpenEBS 0.7 release and has been tested well in the community and in production deployments. The primary function of cStor is to serve iSCSI block storage using the underlying disks or cloud volumes in a cloud native way. cStor is a very light weight and feature rich storage engine. It provides enterprise grade features such as synchronous data replication, snapshots, clones, thin provisioning of data, high resiliency of data, data consistency and on-demand increase of capacity or performance.
When the stateful application desires the storage to provide high availability of data, cStor is configured to have 3 replicas where data is written synchronously to all the three replicas. As shown below, the cStor target is replicating the data to Node1 (R1), Node3(R2) and Node4(R3). The data is written to the three replicas before the response is sent back to the application. It is important to note that the replicas R1, R2 and R3 are copies of the same data written by the target, data is not striped across replicas or across nodes.

When the stateful application itself is taking care of data replication, it is typically deployed as a Kubernetes statefulset. For a statefulset, it is typical to configure cStor with single replica. This is a use case where the use of LocalPV may be preferred.
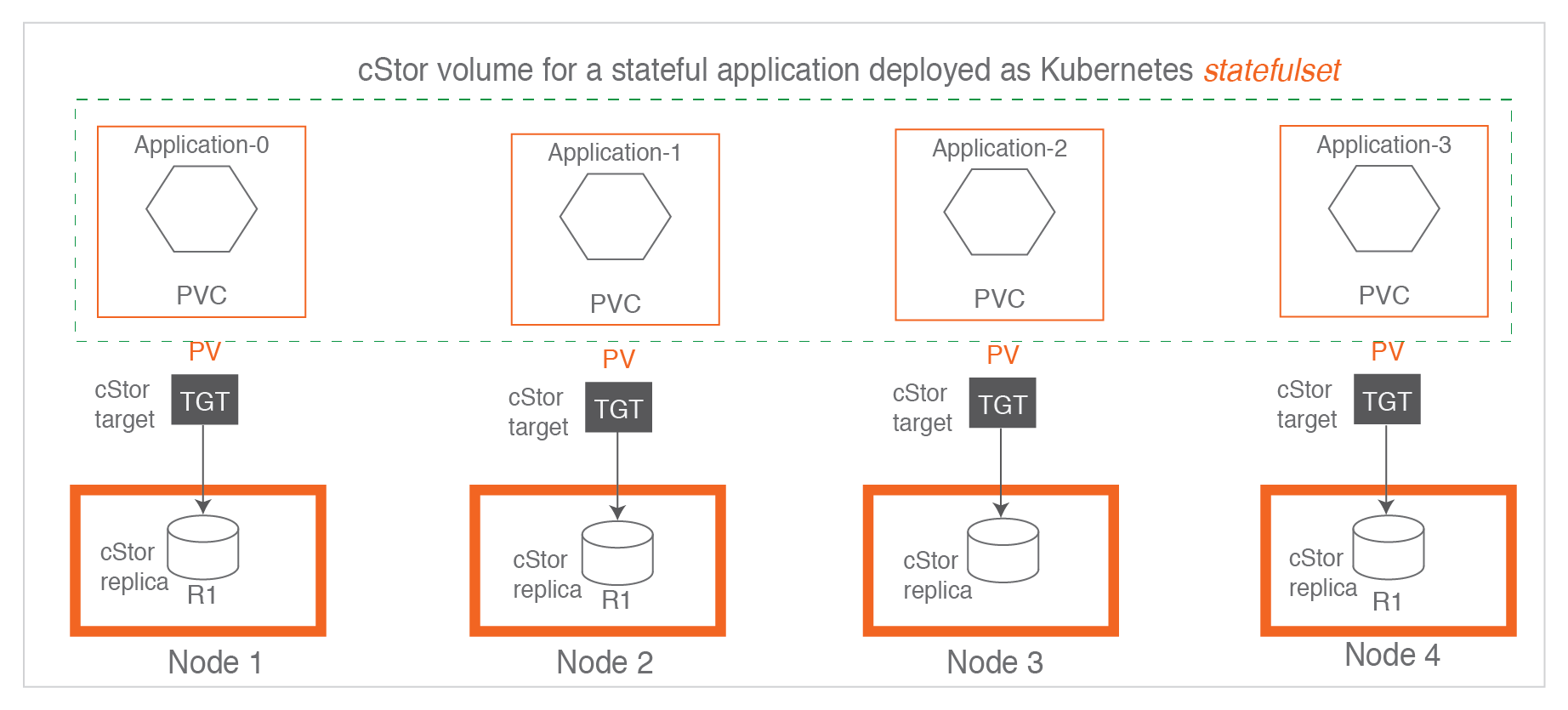
cStor has two main components:
(a) cStor Pool Pods: cStor pool pods are responsible for persisting data into the disks. The cStor pool pods are instantiated on a node and are provided with one or more disks on which data will be saved. Each cStor pool pod can save data of one or more cStor volumes. cStor pool pod carves out space for each volume replica, manages the snapshots and clones of the replica. A set of such cStor pool pods form a single Storage Pool. The administrator will have to create a Storage Pool of type cStor, before creating a StorageClass for cStor Volumes.
(b) cStor Target Pods: When a cStor Volume is provisioned, it creates a new cStor target pod that is responsible for exposing the iSCSI LUN. cStor target pod receives the data from the workloads, and then passes it on to the respective cStor Volume Replicas (on cStor Pools). cStor target pod handles the synchronous replication and quorum management of its replicas.
cStor targets
cStor target runs as a pod and exposes an iSCSI LUN on 3260 port. It also exports the volume metrics that can be scraped by Prometheus.
cStor pools
A cStor pool is local to a node in OpenEBS. A pool on a node is an aggregation of set of disks which are attached to that node. A pool contains replicas of different volumes, with not more than one replica of a given volume. OpenEBS scheduler at run time decides to schedule replica in a pool according to the policy. A pool can be expanded dynamically without affecting the volumes residing in it. An advantage of this capability is the thin provisioning of cStor volumes. A cStor volume size can be much higher at the provisioning time than the actual capacity available in the pool.
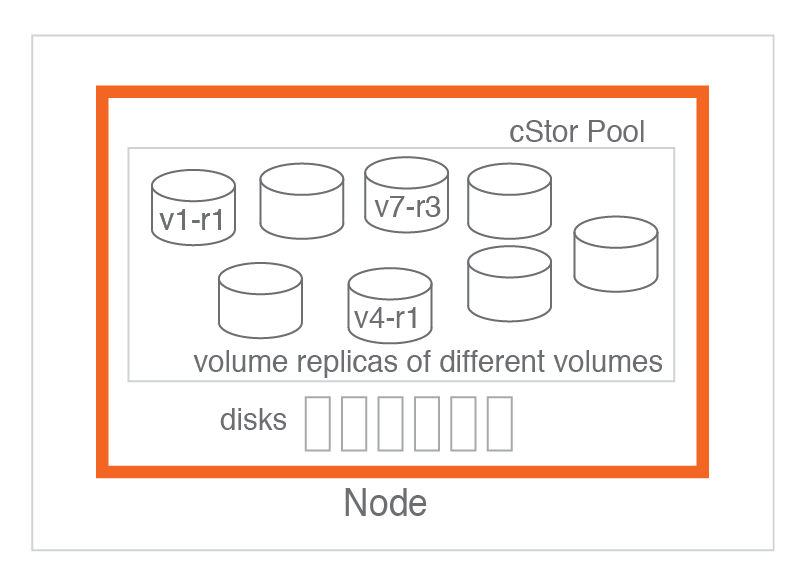
A pool is an important OpenEBS component for the Kubernetes administrators in the design and planning of storage classes which are the primary interfaces to consume the persistent storage by applications.
Benefits of a cStor pool
- Aggregation of disks to increase the available capacity and/or performance on demand.
- Thin provisioning of capacity. Volumes can be allocated more capacity than what is available in the node.
- When the pool is configured in mirror mode, High Availability of storage is achieved when disk loss happens.
Relationship between cStor volumes and cStor pools
cStor pool is a group of individual pools with one pool instance on each participating node. Individual pools in the group are named as pool instances and corresponding pod for each pool instance is referred to as cStor pool pod. The pools are totally independent from each other in that each one is a different pool itself and could host different number of volumes. They simply contain volume replicas. For example, replica3 of pool1 in Node3 has two volumes whereas the other two pool replicas have only one volume each. The pool replicas are related to each other only at the level of target where target decides where to host the volume/data replicas/copies.
Replication of data does not happen at the pool level. Synchronous data replication and rebuilding happen at volume level by the cStor target. Volume replicas are created on cStor pools located on different nodes. In the following example figure, a pool configuration is defined to have three replicas or three independent pools .
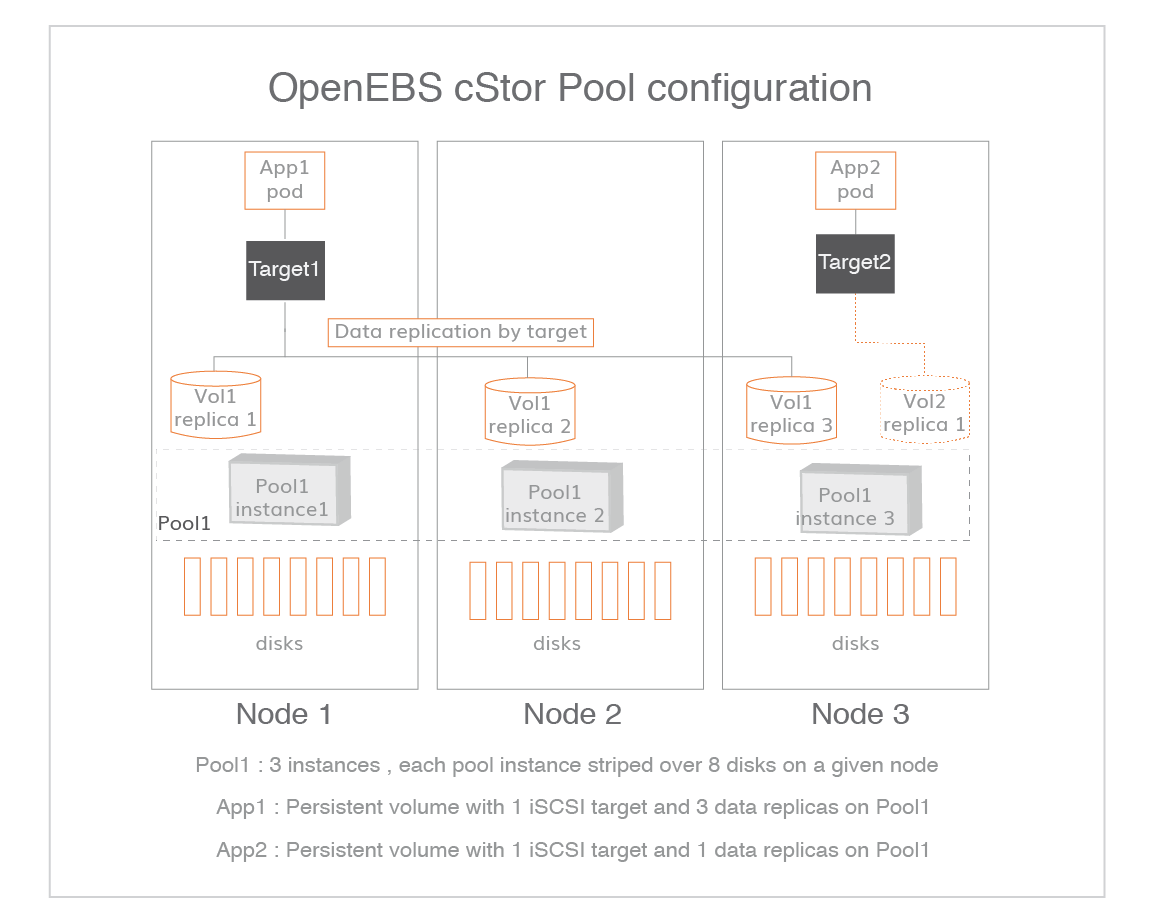
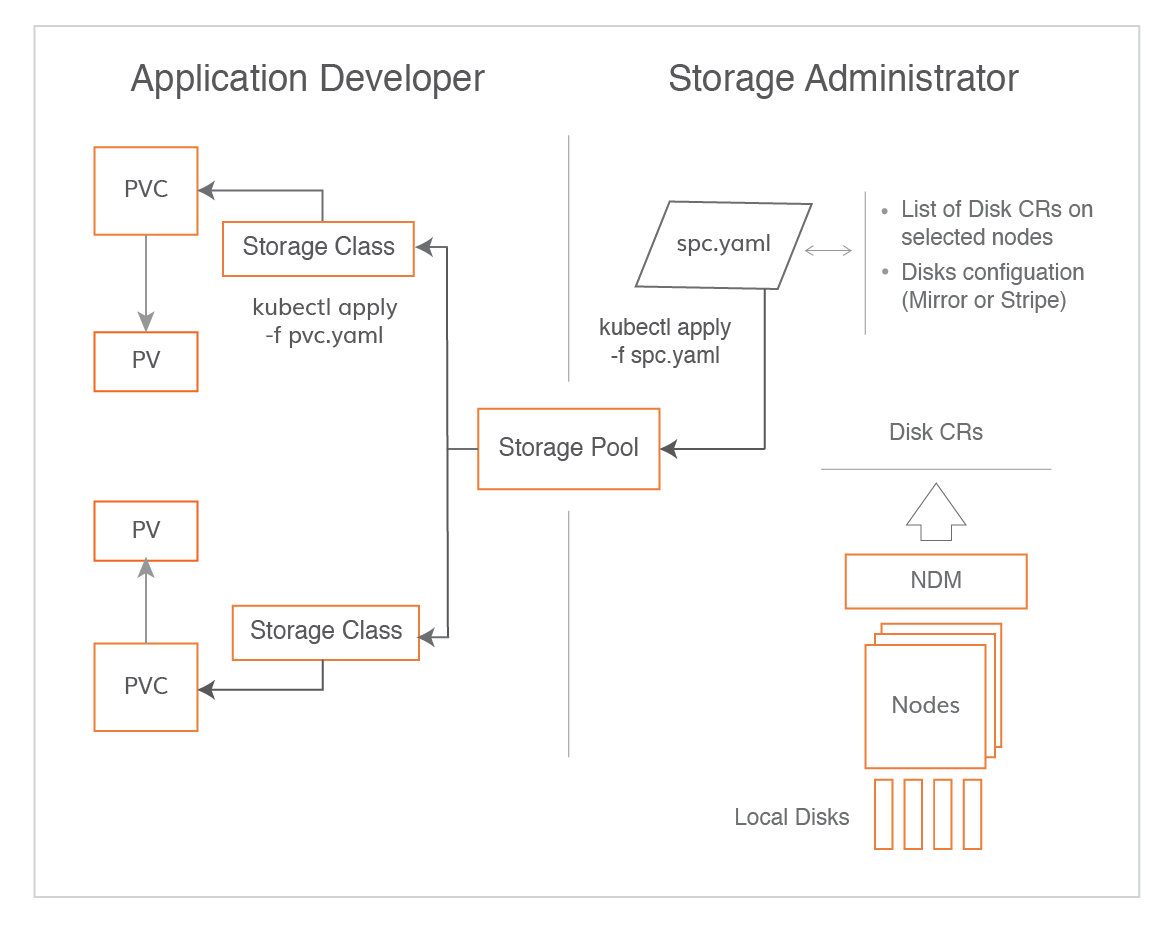
Relationship among PVC, PV, Storage Class, cStor pool and disks
Storage administrators or DevOps administrators first build cStor pools using discovered disks on the designated nodes. Once the pools are built, they are used to design and build storage classes. Application developers then use storage class to dynamically provision PV for the applications.
cStor pool spec details
A cStor pool spec consists of :
- Number of pools
- List of nodes that host the pools
- List of blockdevices on each node that constitute the pool on that given node
- RAID type within the pool. Supported RAID types are striped, mirrored, raidz and raidz2.
Number of pools: It is good to start with 3 pools as the number of volume replicas will be typically three or one. The pool capacity can be increased on the fly and different types of pool expansion can be found here.
List of nodes that host the pools: This information and the number of pool replicas are implicitly provided by analyzing the provided blockdevice CRs in the Storage Pool Claim spec file. For example, if the Storage Pool Claim spec file has 3 blockdevice CRs, which belong to 3 different nodes, it implicitly means the number of pool replicas are 3 and the list of nodes taken from the blockdevice CR's metadata information.
List of blockdevices: This is perhaps the most important information in the pool specification. The blockdevice CRs need to be listed and carefully taken by first determining the list of nodes and the number of disks on each node.
Type of pool: This is also another important configuration information in the pool specification. It defines how these disks are pooled together within a node for creating the Storage pool. Possible configurations are
- STRIPE
- MIRROR
- RAIDZ1
- RAIDZ2
Note: A pool cannot be extended beyond a node. When the pool type is STRIPE, it should not be assumed that data is striped across the nodes. The data is striped across the disks within the pool on that given node. As mentioned in the data replication section, the data is synchronously replicated to as many number of volume replicas in to as many number of pools irrespective of the type of pool.
Operations on cStor Pool
cStor Pool is an important component in the storage management. It is fundamental to storage planning especially in the context of hyperconvergence planning. The following are the different operations that can be performed on cStor Pools.
Create a Pool : Create a new pool with all the configuration. It is typical to start a pool with 3 pool instances on three nodes. Currently RAID types supported for a given pool instance are striped, mirrored, raidz and raidz2. A pool needs to be created before storage classes are created. So, pool creation is the first configuration step in the cStor configuration process.
Add a new pool instance : A new pool instance may need to be added for many different reasons. The steps for expanding a cStor pool to a new node can be found here. Few example scenarios where need of cStor pool expansion to new nodes are:
- New node is being added to the Kubernetes cluster and the blockedvices in new node needs to be considered for persistent volume storage.
- An existing pool instance is full in capacity and it cannot be expanded as either local disks or network disks are not available. Hence, a new pool instance may be needed for hosting the new volume replicas.
- An existing pool instance is fully utilized in performance and it cannot be expanded either because CPU is saturated or more local disks are not available or more network disks or not available. A new pool instance may be added and move some of the existing volumes to the new pool instance to free up some disk IOs on this instance.
Expand a given pool instance : cStor Pool supports thin provisioning, which means that the volume replica that resides on a given cStor pool can be given much bigger size or quota than the physical storage capacity available in the pool. When the actual capacity becomes nearly full (80% or more for example), the pool instance is expanded by adding a set of blockdevices to it. If the pool instance's disk RAID type is STRIPE, then the disks can be added in any multiples of disks (1 disk or more) at a time, but if the type is any of the RAIDZx, then the expansion is done by adding any multiples of RAIDZ groups (1 group or more).
Delete a pool instance : When a Kubernetes node needs to be drained in a planned manner, then the volume replicas in the pool instance that resides on that node need to be drained by moving them to other pool instance(s). Once all the volume replicas are drained, the pool instance can be deleted.
cStor Volume snapshots
cStor snapshots are taken instantaneously as they are point-in-time copy of the volume data. OpenEBS supports standard Kubernetes API to take snapshots and restore volumes from snapshots.
Example specification for a snapshot is shown below.
Note that the snapshot is taken on a PVC and not on PV.
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: snapshot-cstor-volume
namespace: <Source_PVC_namespace>
spec:
persistentVolumeClaimName: cstor-vol1-claim
When the above snapshot specification is run through kubectl it creates two Kubernetes resources.
- Volume snapshot
- Volume snapshot data
Following command is used to list the snapshots in a given namespace
kubectl get volumesnapshots -n <namespace>
Note 1: When cStor volume has three replicas, creation of volume snapshots is possible when the volume is in quorum, which means the at least two of the replicas are online and fully synced.
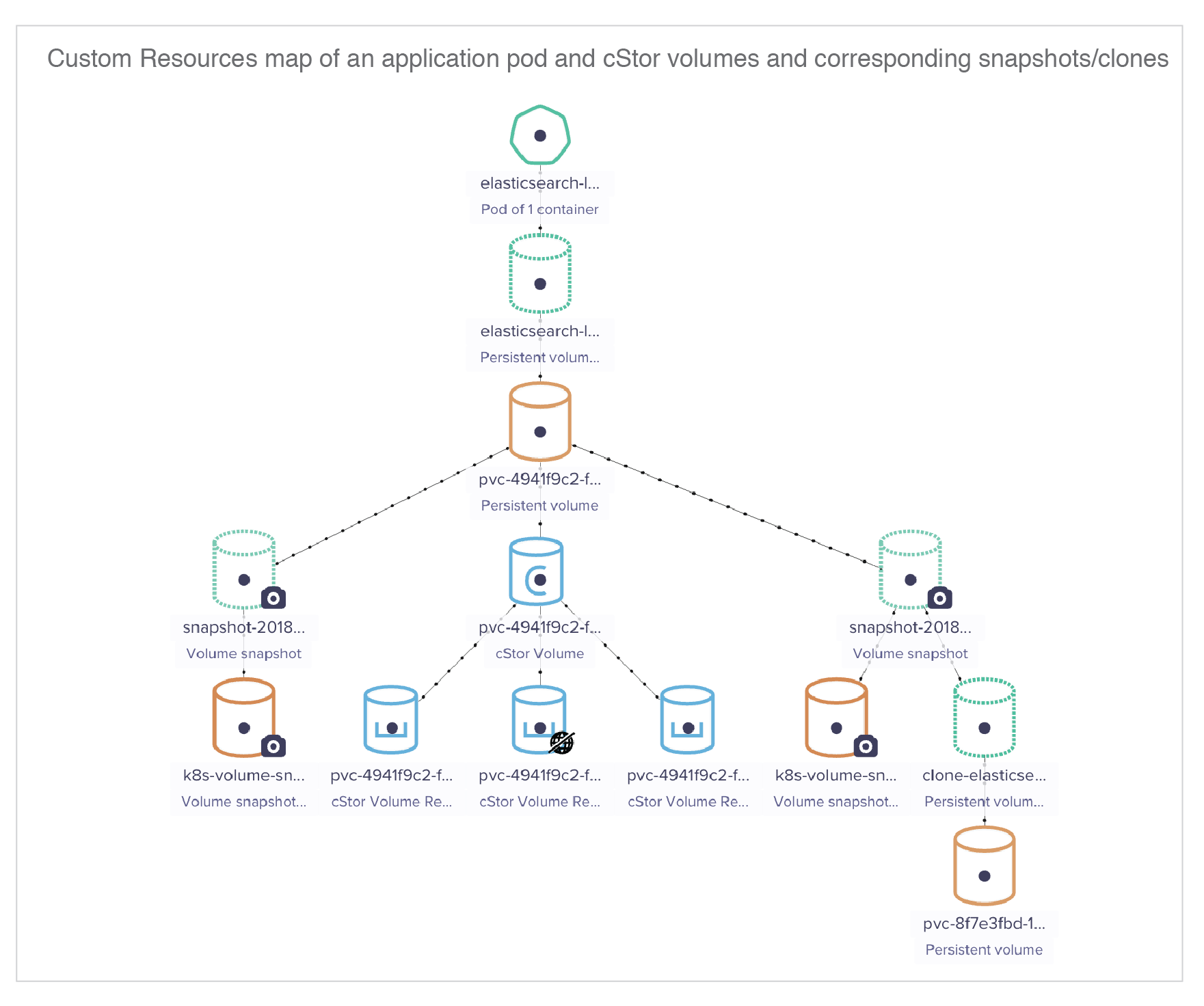
cStor volume clones
Clones in cStor are also instantaneous. They are created in the same namespace as that of the snapshot and belong to the same cStor Pool. In Kubernetes storage architecture, clone from a snapshot is same as creating a new PV.
Example specification for creating a clone out of snapshot
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vol-claim-cstor-snapshot
namespace: <Source_PVC_namespace>
annotations:
snapshot.alpha.kubernetes.io/snapshot: snapshot-cstor-volume
spec:
storageClassName: openebs-snapshot-promoter
For StatefulSet, snapshots are created against each PV. For creating a clone, any one of the snapshot is used in the volumeClaimTemplates specification. Kubernetes will launch the PVs for all the statefulset pods from the chosen snapshot. Example specification for creating a clone out of snapshot for a StatefulSet application is shown below.
volumeClaimTemplates:
- metadata:
name: elasticsearch-logging-clone
annotations:
snapshot.alpha.kubernetes.io/snapshot: snapshot-20181121103439-078f
spec:
storageClassName: openebs-snapshot-promoter
Note: One can mix and match the snapshots between deployments and statefulsets while cloning. For example, a snapshot taken using the PVC of a deployment can be used to clones for statefulset.
cStor cli
| CLI command | Purpose or remarks |
|---|---|
| kubectl get spc | Get the list of storage pool claims (SPC is the spec for each cStor storage pool) |
| kubectl get csp | Get the list of storage pools (cstor storage pools). One SPC refers to one or more CSPs. If there are two pools - cstor-ssd-pool on 3 nodes and cstor-sas-pool on 4 nodes, then there will be two SPCs and 7 CSPs |
| kubectl get blockdevice --labels | Get the list of all blockdevice CRs in the entire cluster |
| kubectl get cstorvolume -n openebs | Get the list of cStor volumes in the entire cluster |
| kubectl get cvr -n openebs | Get the list of cStor volumes in the entire cluster |
| kubectl get volumesnapshot | Get the list of volumesnapshots in the entire cluster |
High Availability of cStor
cStor volumes when deployed in 3 replica mode, it provides high availability of data as long as the replicas are in quorum. At least two replicas are required to be healthy to call the volume is in quorum. In a 3 replicas setup, if two replicas becomes unavailable due to either pool failure or unavailability, the volume is set to read-only by the target. When the volume replicas are back online, it will start rebuilding data from the healthy replica one by one and the volume is set to be read-write as soon as the quorum is achieved.
Ephemeral Disk Support
Kubernetes services such as GKE, EKS and AKS have cloud VMs where when a node is lost a new replacement node is provided with formatted new blockdevice as part of their Auto Scaling policy which means that the data on local disks of the original node is lost permanently. However, with cStor, you can still build a reliable and highly available persistent storage solution using these ephemeral local disks by using cStor's replication feature.
For this to work, cStor StorageClass has to be configured with ReplicaCount=3. With this setting data on cStor volume is replicated to three copies on different nodes. In the ephemeral nodes scenario, when a node is lost, Kubernetes brings up a new node with the same label. Data of cStor volumes continues to be available and will be served from one of the other two remaining replicas. OpenEBS detects that a new node has come up with all new disks and it will automatically reconfigure the blockdevices CR to the existing StoragePoolClaim config or StoragePool configuration. The net effect is that the cStorPool instance that was gone with the lost node is recreated on the newly replaced node. cStor will then start rebuilding the cStor volume replicas onto this new cStorPool instance.
Note: Rebuilding of data onto the new cStorPool instance can take time depending on the amount of data to be rebuilt. During this time the volume quorum needs to be maintained. In other words, during rebuilding time, the cStorPool is in an unprotected state where losing another node will cause permanent loss of data. Hence, during Kubernetes node upgrades, administrators need to make sure that the cStorPools are fully rebuilt and volumes are healthy/online before starting the upgrade of the next node.
Thin provisioning in cStor
cStor supports thin provisioning of volumes. By default, a volume is provisioned with whatever capacity that is mentioned in StorageClass. Capacity of the pool can be expanded on demand by adding more disks to the cStor pool. cStor architecture also supports the resizing of a provisioned volume on the fly using CSI provisioner supported cStor volume.
Performance testing of cStor
Performance testing includes setting up the pools, StorageClasses and iSCSI server tunables. Some best practices include
Number of replicas - For Statefulsets, when the application is doing the required replication, one replica per volume may be sufficient
Network latency - Latency between the pods and zones (if the replicas are placed across AZs) plays a major role in the performance results and it needs to be in the expected range
Known limitations
After a node shutdown, I see application stuck in container creating waiting for PV to be attached.:
When a Kubernetes node is involved in an unplanned shutdown like a power loss or software hang etc, the PVs which are mounted on that node will not be mounted by Kubelet till the timeout of 30 minutes or 1800 seconds. In such scenarios, the application will lose connectivity to persistent storage. This limitation of Kubernetes will be resolved for OpenEBS PVs when the CSI driver support is available for OpenEBS. With OpenEBS CSI driver in place, the unavailability of the node can be detected by the CSI driver node agent and do the force mount of the PV on the new node. The alpha version of CSI support is available from OpenEBS 1.2.0.
Cannot disable thin provisioning
By default, cStor supports thin provisioning, which means that when a storage class or PVC specifies the size of the volume and the pool from which the volume must be provisioned, and volume of that size is provisioned irrespective of whether that much free space is available in the pool or not. There is no option to specify thick provision while requesting a volume provisioning.
Delayed snapshots
In cStor, snapshots are taken only when the volume replicas are in quorum. For example, as soon as the volume is provisioned on cStor, the volume will be in ready state but the quorum attainment may take few minutes. Snapshot commands during this period will be delayed or queued till the volumes replicas attain quorum. The snapshot commands received by the target are also delayed when the cStor volume is marked read-only because of no-quorum.
Troubleshooting areas
Following are most commonly observed areas of troubleshooting
iSCSI tools are not installed or iscsi.d service is not running
Symptom:
If iSCSI tools are not installed on the nodes, after launching the application with PVC pointing to OpenEBS provisioner, you may observe the application is in "ContainerCreating" state.
kubectl describe pod <app pod>may give an error that looks like the followingMountVolume.WaitForAttach failed for volume "pvc-33408bf6-2307-11e9-98c4-000d3a028f9a" : executable file not found in $PATHResolution:
Install iSCSI tools and make sure that iSCSI service is running. See iSCSI installation
Multi-attach error is seen in the logs
Symptom:
In a node failure case, it is sometimes observed that the application pods that were running on the node that went down are moved, the cStor target pods are also moved to other nodes, but the application throws up an error similar to below:
Warning FailedAttachVolume 4m15s attachdetach-controller Multi-Attach error for volume "pvc-d6d52184-1f24-11e9-bf1d-0a0c03d0e1ae" Volume is already exclusively attached to one node and can't be attached to anotherResolution :
This is because of the Kubernetes limitation explained above. OpenEBS CSI driver will resolve this issue. See roadmap. In this situation if the node is stuck in a non-responsive state and if the node has to be permanently deleted, remove it from the cluster.
Application is in ContainerCreating state, observed connection refused error
Symptom:
Application is seen to be in the
ContainerCreatingstate, with kubectl describe showingConnection refusederror to the cStor PV.Resolution:
This error eventually could get rectified on the further retries, volume gets mounted and application is started. This error is usually seen when cStor target takes some time to initialize on low speed networks as it takes time to download cStor image binaries from repositories ( or ) or because the cstor target is waiting for the replicas to connect and establish quorum. If the error persists beyond 5 minutes, logs need to be verified, contact OpenEBS Community for support.
Kubelet seen consuming high RAM usage with cStor volumes
The cause of high memory consumption of Kubelet is seen on Fedora 29 mainly due to the following.
There are 3 modules are involved -
cstor-isgt,kubeletandiscsiInitiator(iscsiadm). kubelet runs iscsiadm command to do discovery on cstor-istgt. If there is any delay in receiving response of discovery opcode (either due to network or delay in processing on target side), iscsiadm retries few times and gets into infinite loop dumping error messages as below:iscsiadm: Connection to Discovery Address 127.0.0.1 failed iscsiadm: failed to send SendTargets PDU iscsiadm: connection login retries (reopen_max) 5 exceeded iscsiadm: Connection to Discovery Address 127.0.0.1 failed iscsiadm: failed to send SendTargets PDUkubelet keeps taking this response and accumulates the memory.More details can be seen here.
Resolution:
This issue is fixed in 0.8.1 version.
cStor roadmap
| Feature | Release |
|---|---|
| cStor Pool features | |
| cStor pool creation and initial use with either stripe mode or RAIDZ0 (mirror) mode | 0.8.0 |
| Adding a new cStorPool instance to the existing cstor-pool-config(SPC) | 0.8.1 |
| Ephemeral disk/pool support for rebuilding | 0.8.1 |
| Expanding a given pool replica (add disks to a pool after it is created) (Alpha) | 1.2.0 |
| Support for RAIDZ1 in cStorPool | 1.1.0 |
| Support for RAIDZ2 in cStorPool | 1.1.0 |
| Deleting a pool replica (Alpha) | 1.2.0 |
| Disk replacement in a given cStor pool instance created using CSPC way(Alpha) | 1.5.0 |
| cStor volume features | |
| Expanding the size of a cStor volume using CSI provisioner (Alpha) | 1.2.0 |
| CSI driver support(Alpha) | 1.1.0 |
| Snapshot and Clone of cStor volume provisoned via CSI provisioner(Alpha) | 1.4.0 |
| Scaling up of cStor Volume Replica | 1.3.0 |
| Scaling down of cStor Volume Replica | 1.4.0 |
Advanced concepts in cStor
Custom resources related to cStor
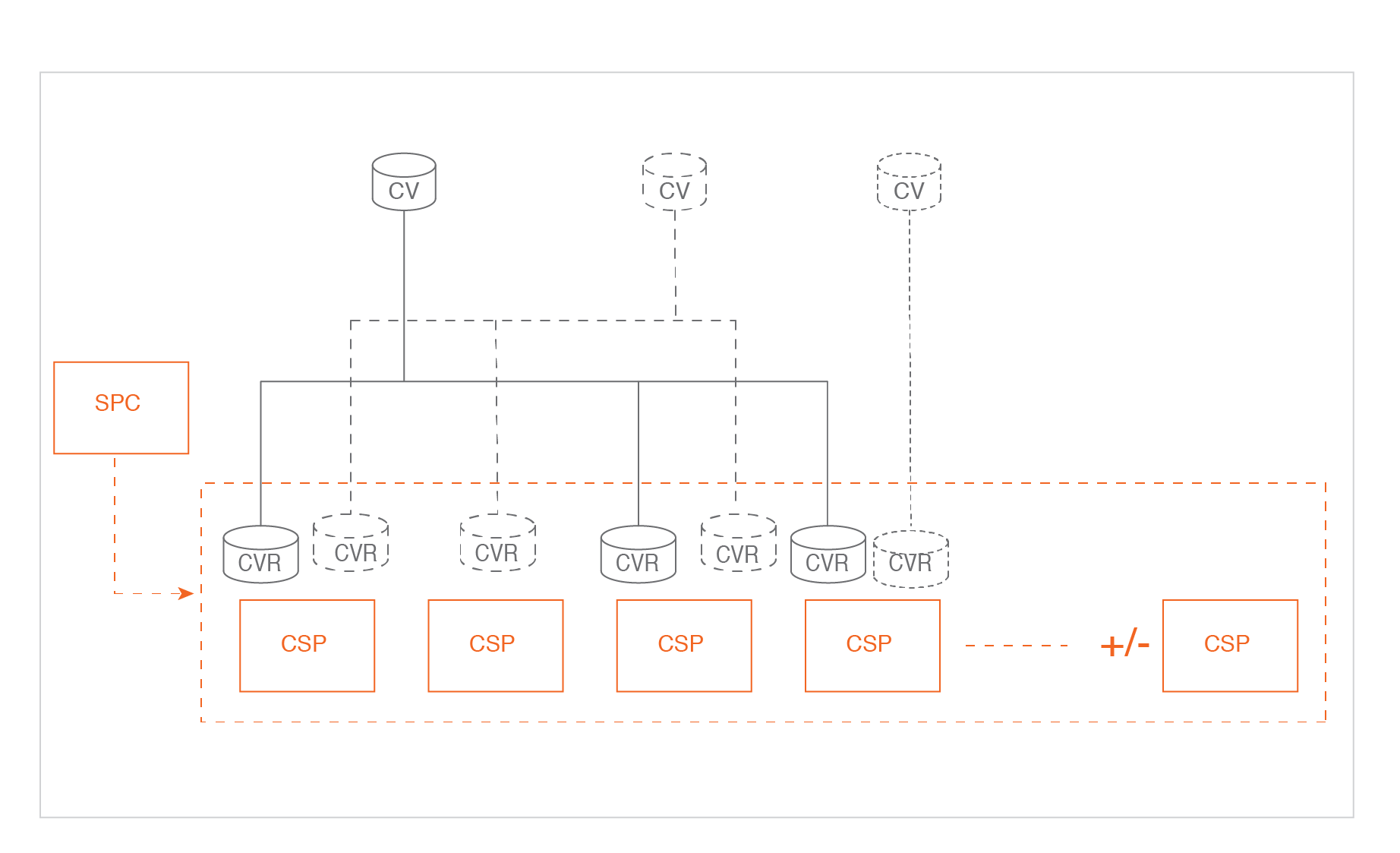
Storage Pool Claim or SPC:
Pool specification or Pool aggregate that holds all CSPs together
cStor Storage Pool or CSP :
An individual cStor pool on one node. There will also be a cStor-Pool pod corresponding to each CSP custom resource. When a new node is added to the Kubernetes cluster and configured to host a cStor pool, a new CSP CR and a cStor Pool Pod are provisioned on that node and CVRs are migrated from other nodes for volume rebalancing. (CSP auto scaling feature is in the roadmap)
cStor Volume or CV :
An individual persistent volume. For each PV provisioned through CAS type as cStor, there will be a corresponding CV custom resource
cStor Volume Replica or CVR :
Each CV will have as many CVRs as the number of replicas configured in the corresponding cStor storage class.
Blockdevice :
Each discovered blockdevice on a node is added as a blockdevice CR. This is needed to identify a blockdevice uniquely across the Kubernetes cluster. SPC specification contains the information about the blockdevice CRs that correspond to a CSP on that given node
See Also:
Storage Engines in OpenEBS
Creating cStor Pool
Provisioning cStor volumes
Feedback
Was this page helpful?
Thanks for the feedback. Open an issue in the GitHub repo if you want to report a problem or suggest an improvement. Engage and get additional help on https://kubernetes.slack.com/messages/openebs/.